Adapting prompts across LLMs
Prompt adaptation is in private beta
Please reach out to us if you want to test it out!
Migrating applications from one LLM to another requires extensive, tedious prompt engineering to avoid performance degradation. Not Diamond can help you automatically adapt your prompts from the original model to a new target LLM.
In order to adapt prompts from one model to another, you will need the following:
- A Not Diamond API key.
- Your original prompt
- An evaluation dataset and metric for measuring the quality of LLM responses
- A list of target models you want to adapt to
The example below shows how we can adapt a RAG workflow originally built for OpenAI's GPT-4o on the repliqa dataset, to work optimally on Anthropic's Claude 3.5 Sonnet.
Setup
First, we will download repliqa from Huggingface.
from datasets import load_dataset
n_samples = 100
ds = load_dataset("ServiceNow/repliqa")["repliqa_0"].select(list(range(n_samples)))
Minimum of 25 samples required
Prompt adaptation currently requires at least 25 training samples to work effectively. You can submit up to 200 samples for a given request. Note that larger datasets will result in longer job times.
Next, we define the system prompt and prompt template for our current workflow.
system_prompt = """You are a researcher answering questions from the given document.
Please answer the question based on the contents of the document.
Make sure to read the document carefully before answering the question.
Do not use any external knowledge.
For each question, present the reasoning followed by the correct answer.
If the answer to the question can not be obtained from the provided context paragraph, output 'UNANSWERABLE'.
"""
prompt_template = """
Document: {document}
Question: {question}
"""
Finally, we'll define some helper functions to help us call the adaptation APIs.
SDK support coming soon
Prompt adaptation support in our Python SDK is coming soon. Please contact us if you would like to test this new SDK feature.
from typing import List, Dict, Any, Optional
import requests
import json
def request_prompt_adaptation(
system_prompt: str,
prompt_template: str,
fields: List[str],
train_data: List[Dict[str, str | Dict[str, str]]],
origin_model: Dict[str, str],
target_models: List[Dict[str, str]],
notdiamond_api_key: str,
evaluation_metric: Optional[str] = None,
evaluation_config: Optional[Dict] = None,
request_url: str = "https://api.notdiamond.ai/v2/prompt/adapt"
) -> str:
"""
Helper method to call the prompt adaptation endpoint
"""
if (evaluation_metric and evaluation_config) or (not evaluation_metric and not evaluation_config):
raise ValueError("Either evaluation_metric or evaluation_config must be provided, but not both or neither.")
request_body = {
"system_prompt": system_prompt,
"template": prompt_template,
"fields": fields,
"goldens": train_data,
"origin_model": origin_model,
"target_models": target_models,
}
if evaluation_metric:
request_body["evaluation_metric"] = evaluation_metric
if evaluation_config:
request_body["evaluation_config"] = json.dumps(evaluation_config)
headers = {
"Authorization": f"Bearer {notdiamond_api_key}",
"content-type": "application/json"
}
resp = requests.post(
request_url,
headers=headers,
json=request_body
)
if resp.status_code == 200:
response = resp.json()
return response["adaptation_run_id"]
else:
raise Exception(
f"Request to adapt prompt failed with code {resp.status_code}: {resp.text}"
)
def get_prompt_adaptation_results(
adaptation_run_id: str,
notdiamond_api_key: str,
request_url: str = "https://api.notdiamond.ai/v2/prompt/adaptResults"
) -> Dict[str, Any]:
"""
Helper method to get the results of a prompt adaptation request
"""
headers = {
"Authorization": f"Bearer {notdiamond_api_key}",
"content-type": "application/json"
}
resp = requests.get(
f"{request_url}/{adaptation_run_id}",
headers=headers
)
if resp.status_code == 200:
response = resp.json()
return response
else:
raise Exception(
f"Requesting prompt adaptation result failed with code {resp.status_code}: {resp.text}"
)
Evaluation metrics
Our prompt adaptation tool will optimize prompts against one of several possible metric parameters.
LLM-judged metrics
Several metrics use LLM judging to score outputs:
"LLMaaJ:Sem_Sim_1": This metric uses an LLM-as-a-judge to evaluate the semantic similarity of the model response relative to the target golden and outputs a binary score (0 or 1) depending on whether or not the two answers are semantically similar or not. This is the default metric."LLMaaJ:Sem_Sim_10": This metric uses an LLM-as-a-judge to evaluate the semantic similarity of the model response relative target golden on a scale of 1-10."LLMaaJ:SQL": This metric uses an LLM-as-a-judge to evaluate whether the SQL generated is correct based on the question asked."LLMaaJ:Unsupervised_Correctness_1": This metric uses an LLM-as-a-judge to evaluate the correctness of an LLM response to a question. Similar to"LLMaaJ:Sem_Sim_1"the score is binary (0 or 1) depending on whether the response satisfies the question but no target golden is needed.
Prompts for each of these metrics can be found in the tabs below. By default, we use openai/gpt-4o-2024-08-06 as the judge.
Given the predicted answer and reference answer, compare them and check whether they mean the same.
Following are the given answers:
Predicted Answer: {predicted_answer}
Reference Answer: {gt_answer}
On a NEW LINE, give a score of 1 if the answers mean the same, and 0 if they differ, and nothing more.
You are a smart language model that evaluates the similarity between a predicted text and the expected ground truth answer. You do not propose changes to the answer and only critically evaluate the existing answer and provide feedback following the instructions given.
The following is the response provided by a language model to a prompt:
{predicted_answer}
The expected answer to this prompt is:
{gt_answer}
Answer only with an integer from 1 to 10 based on how semantically similar the responses are to the expected answer. where 0 is no semantic similarity at all and 10 is perfect agreement between the responses and the expected answer. On a NEW LINE, give the integer score and nothing more.
Below is a question that asks to generate a SQL query to answer a question.
Based on the question, determine if the generated SQL produces the same outcome as the correct SQL.
Look for the SQL query enclosed in <ANS_START> and <ANS_END> in the generated SQL.
Question:
{question}
Generated SQL:
{predicted_answer}
Correct SQL:
{gt_answer}
On a NEW LINE, give a score of 1 if the generated SQL produces the same outcome as the correct SQL, and 0 if they differ, and nothing more.
## Instructions
You are a helpful assistant that evaluates the correctness of a response to a question.
Please provide a score of 1 if the response is correct, and 0 if it is incorrect.
## Criteria
- Use information provided in the question to evaluate the response.
- If the question includes reference text which should be used to answer it, ensure that the answer
is based on the reference text. In this scenario, **the answer is incorrect if it is not based
on the reference text.**
- If the question does not include reference text, you can evaluate the answer based on your knowledge.
- Do not provide any other text in your response. Only output the numeric score of 0 or 1.
## Examples
Question: What is the capital of France?
Response: Paris
Score: 1
# In the example below, the answer is incorrect because it is not based on the reference text.
Question: Assume the capital of France is Berlin. What is the capital of France?
Response: Paris
Score: 0
Question: The meaning of life is 42. What is the meaning of life?
Response: 42
Score: 1
# In the example below, the answer is incorrect because it is not based on the reference text.
Question: The meaning of life is 42. What is the meaning of life?
Response: It can be difficult to reason about a subjective topic like this...
Score: 0
## Evaluation
Question: {question}
Response: {predicted_answer}
Score:
Matching metrics
"JSON_Match": This metric determines if the LLM's JSON output matches the golden JSON output. We computeprecision,recall, andf1scores based on individual fields in the JSON and averaged across all samples in the dataset. This is useful for applications that require structured outputs.
More evaluation metrics coming soon
If you need to support a custom evaluation metric, please reach out to us and we will onboard it for you.
Custom LLM-as-a-judge metrics
If you have a custom LLM-as-a-judge metric you would like to use, you can specify an "evaluation_config" instead of an "evaluation_metric". The "evaluation_config" should consist the following
llm_judging_prompt: The custom prompt for the LLM judge. The prompt must contain a{question}and an{answer}field. The{question}field is used to insert the formatted prompts from your dataset and the{answer}field is used to insert the LLM's response to the question.llm_judge: The LLM judge to use for evaluation, in"provider/model"format. The list of supported LLMs can be found below in Supported models.correctness_cutoff: The cutoff score above which the response is deemed correct. For example, if the judging score is from 1 to 10, you might set the cutoff at 8.
An example of this is shown below
evaluation_config = {
"llm_judging_prompt": (
"Does the assistant's answer properly answer the user's question? question: {question} answer: {answer} "
"Score a 1 if the answer is correct, 0 otherwise. Do not output any other values or text - only the score."
),
"llm_judge": "openai/gpt-4o-2024-11-20",
"correctness_cutoff": 0,
}
Request prompt adaptation
First we will format the dataset for prompt adaptation. Not Diamond expects a list of samples consisting of prompt template field arguments, so ensure that prompt_template.format(sample['fields']) returns a valid user prompt for each sample.
fields = ["document", "question"]
pa_ds = [
{
"fields": {
"document": sample["document_extracted"],
"question": sample["question"]
},
"answer": sample["answer"]
}
for sample in ds
]
print(prompt_template.format(**pa_ds[0]['fields']))
Next, specify the origin_model which you query with the current system prompt and prompt template; and your target_models, which you would like to query with adapted prompts. You can list multiple target models.
origin_model = {"provider": "openai", "model": "gpt-4o-2024-08-06"}
target_models = [
{"provider": "anthropic", "model": "claude-3-5-sonnet-20241022"},
]
Use multiple target models for the best results
Our prompt adaptation API allows you to define up to 4 target models. If you're unsure about which model you should migrate to, defining multiple target models lets you see at a glance which model is best suited for your data.
Supported models
Prompt adaptation currently only supports adapting prompts to the following target models:
openai/gpt-4o-2024-08-06openai/gpt-4o-2024-11-20openai/gpt-4o-mini-2024-07-18openai/gpt-4.1-2025-04-14openai/gpt-4.1-mini-2025-04-14openai/gpt-4.1-nano-2025-04-14anthropic/claude-3-5-sonnet-20241022anthropic/claude-3-7-sonnet-20250219anthropic/claude-sonnet-4-20250514anthropic/claude-opus-4-20250514google/gemini-1.5-pro-latestgoogle/gemini-2.5-flashgoogle/gemini-2.5-promistral/mistral-large-2411qwen/qwen3-14bqwen/qwen3-32bqwen/qwen3-235b-a22bmeta-llama/llama-3.1-8b-instructmeta-llama/llama-3.1-70b-instructmeta-llama/llama-3.1-405b-instruct
Finally, call the API with your NOTDIAMOND_API_KEY and the adaptation request will be submitted to Not Diamond's servers. You will get back a prompt_adaptation_id.
Please only submit one job at a time
Prompt adaptation is still in beta and our endpoint is not designed for high-volume production traffic. Please submit only one job at a time and wait for it to complete before submitting another job. It is fine for a single job to include multiple target models.
prompt_adaptation_id = request_prompt_adaptation(
system_prompt=system_prompt,
prompt_template=prompt_template,
fields=fields,
train_data=pa_ds,
origin_model=origin_model,
target_models=target_models,
evaluation_metric="LLMaaJ:Sem_Sim_1",
notdiamond_api_key="YOUR_NOTDIAMOND_API_KEY"
)
prompt_adaptation_id = request_prompt_adaptation(
system_prompt=system_prompt,
prompt_template=prompt_template,
fields=fields,
train_data=pa_ds,
origin_model=origin_model,
target_models=target_models,
evaluation_config=evaluation_config,
notdiamond_api_key="YOUR_NOTDIAMOND_API_KEY"
)
Request status
Get adapted prompt and evaluation results
Once the prompt adaptation request is completed, you can request the results of the optimization using the same prompt_adaptation_id.
results = get_prompt_adaptation_results(prompt_adaptation_id, "YOUR_NOTDIAMOND_API_KEY")
print(results)
The response will return a dictionary with the following fields:
{
"id": "uuid", // The prompt adaptation id
"created_at": "datetime", // Timestamp
"origin_model": {
"model_name": "openai/gpt-4o-2024-11-20", // The original model the prompt was designed for
"score": 0.8, // The original model's score on the dataset before optimization
"evals": {"LLMaaJ:Sem_Sim_1": 0.8}, // The original model's evaluation results on the dataset
"system_prompt": "...", // The baseline system prompt submitted
"user_message_template": "...", // The baseline prompt template submitted
"result_status": "completed"
},
"target_models": [
{
"model_name": "anthropic/claude-3-5-sonnet-20241022", // The original model the prompt was designed for
"pre_optimization_score": 0.64, // The target model's score on the dataset before optimization
"pre_optimization_evals": {"LLMaaJ:Sem_Sim_1": 0.64}, // The target model's evaluation results on the dataset before optimization
"post_optimization_score": 0.8, // The target model's score on the dataset after optimization
"post_optimization_evals": {"LLMaaJ:Sem_Sim_1": 0.8}, // The targe model's evaluation results on the dataset after optimization
"system_prompt": "...", // The baseline system prompt submitted
"user_message_template": "...", // The baseline prompt template submitted
"user_message_template_fields": ["..."], // Field arguments in the user_message_template
"result_status": "completed"
}
],
}
result_status can have one of the following statuses:
processing: the optimization job is currently running. Evaluation scores will benulluntil the job iscompleted.completed: the optimization job is finished and you will see the evaluation scores populated.failed: the optimization job failed, please try again or contact support.
Each model in target_models will have its own results dictionary. If an adaptation failed for a specific target model, please try again or contact support.
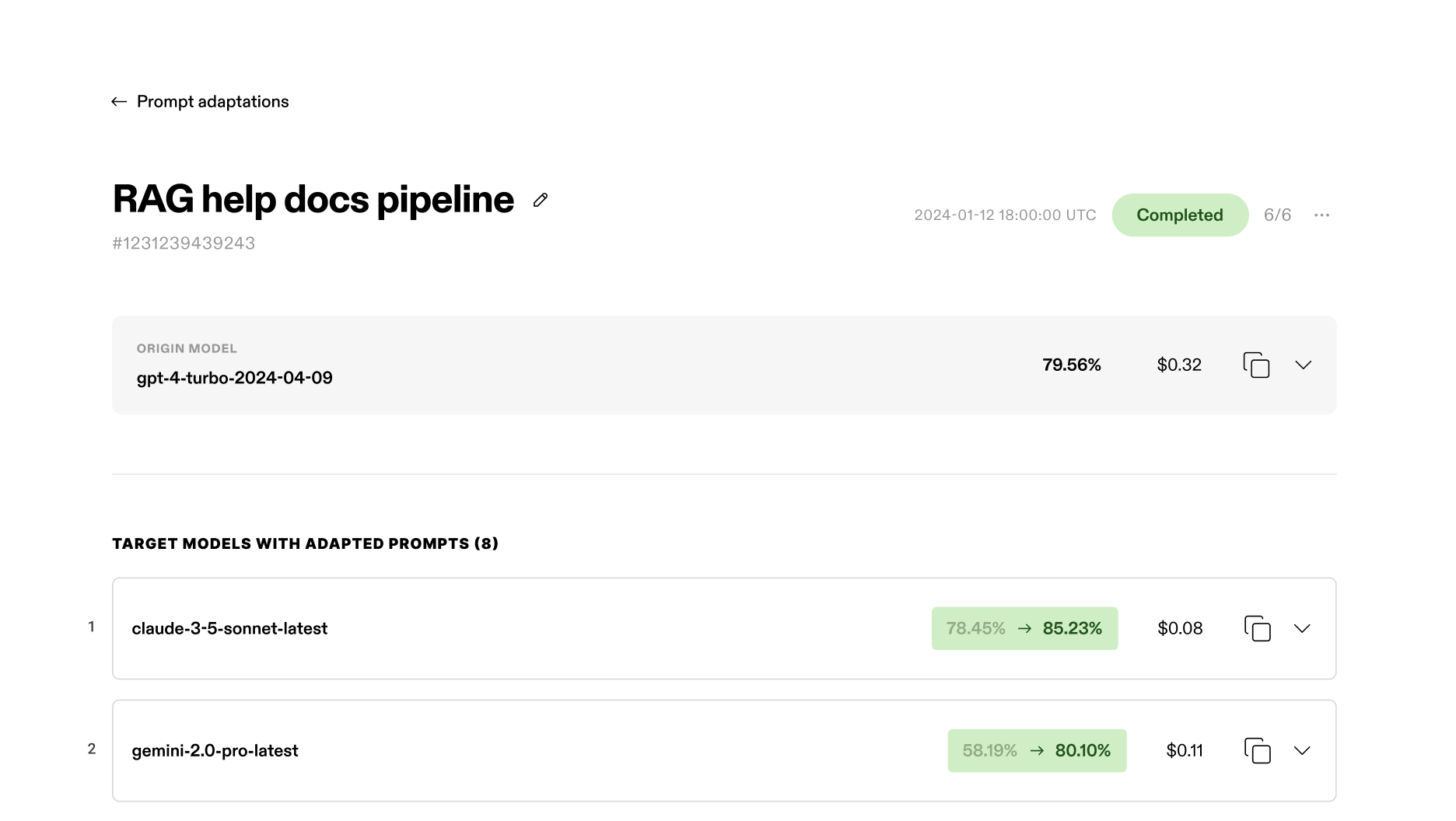
View your prompt adaptation requests and results
Prompt adaptation dashboard
Not Diamond will soon provide a dashboard interface for your prompt adaptation requests and results.
Updated about 2 months ago