How Not Diamond works
For any distribution of data, rarely will one single model outperform every other model on every single query. Not Diamond works by combining together multiple models into a "meta-model" that learns when to call each LLM, outperforming every individual model’s performance and driving down costs and latency by leveraging smaller, cheaper models when doing so doesn't degrade quality.
To determine the best LLM to recommend for each input, we need to provide a dataset that includes a set of inputs, responses from our candidate LLMs, and scores on those responses using any evaluation metric of our choosing. We can use this data to train a custom router that learns a mapping from inputs to rankings for candidate models. For novel inputs our routing algorithm will then predict the top-ranked model for that query.
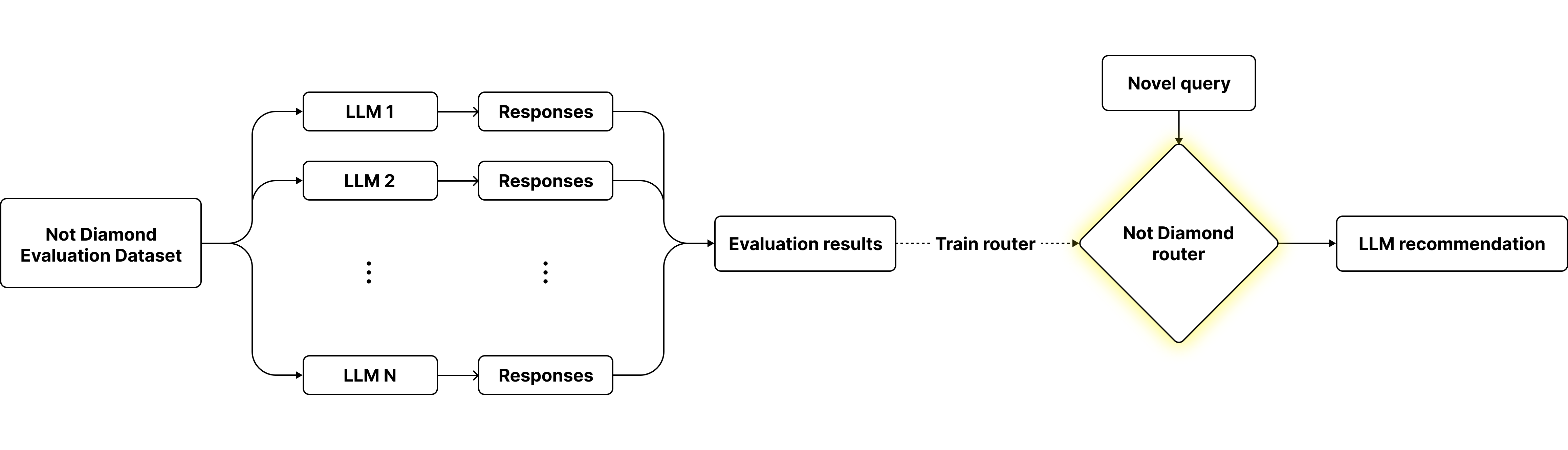 By default, Not Diamond's routing algorithm maximizes response quality. Depending on our business needs, we can then dynamically adjust cost or latency tradeoffs using Pareto optimization techniques.
By default, Not Diamond's routing algorithm maximizes response quality. Depending on our business needs, we can then dynamically adjust cost or latency tradeoffs using Pareto optimization techniques.
Updated 15 days ago