Agent workflows
Not Diamond is particularly powerful when used in combination with agent workflows, in which chains of LLM ingest unforeseen prompts across a diversity of use cases and domains.
In this example, we will largely follow LangGraph's Agentic RAG tutorial. The main difference is that we will use Not Diamond to route calls on each step and improve routing decisions based on real-time feedback.
Installation
We'll start by installing the packages needed for this example:
pip install -U notdiamond[create] langchainhub langgraph chromadbWe'll also create a agent.py with the following import statements:
from typing import Annotated, Literal, Sequence, TypedDict, Optional
import pprint
import requests
import os
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.tools.retriever import create_retriever_tool
from langchain_core.messages import BaseMessage
from langchain_core.prompts import PromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langgraph.graph import START, END, StateGraph
from langgraph.prebuilt import ToolNode, tools_condition
from langgraph.graph.message import add_messages
from notdiamond import LLMConfig, NotDiamond, MetricInitialization
We'll start by creating a retrieval agent which can decide whether to retrieve from an index using a retriever tool. To do this, we'll index several blog posts and create a retriever tool:
# Define blog post urls to load
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
# Load documents from URLs using WebBaseLoader
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
# Split documents into chunks using RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=100, # Split into chunks of 100 characters
chunk_overlap=50 # Overlap chunks by 50 characters
)
doc_splits = text_splitter.split_documents(docs_list)
# Initialize Chroma vectorstore with the split documents and OpenAIEmbeddings
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OpenAIEmbeddings(),
)
# Convert the vectorstore into a retriever
retriever = vectorstore.as_retriever()
# Create a retriever tool
retriever_tool = create_retriever_tool(
retriever,
"retrieve_blog_posts",
"""
Search and return information about Lilian Weng blog posts on LLM agents,
prompt engineering, and adversarial attacks on LLMs.
""",
)
# Store the retriever tool in a list compatible with OpenAI and Not Diamond's tool format
tools = [retriever_tool]Agent state
LangGraph uses graphs to define a set of nodes and edges. A state object is passed to and updated by each node. In our case, we'll define the state to include of a list of messages, session_ids, LLM providers used, and the nodes visited (the entire trajectory of the agent up to that point). Note that session_id and LLM providers are used to provide feedback to Not Diamond.
# helper function to append session ids, providers, and node names
def add_nd_params(a: list, b: str | LLMConfig | None) -> list:
if b is not None:
a.extend(b)
return a
class AgentState(TypedDict):
# add_messages and add_nd_params define how an update should be processed
# Default is to replace. Here, we instead append
messages: Annotated[Sequence[BaseMessage], add_messages]
session_ids: Annotated[Sequence[str], add_nd_params]
providers: Annotated[Sequence[LLMConfig], add_nd_params]
node_name: Annotated[Sequence[str], add_nd_params]Nodes and edges
Next, we'll define the nodes and edges of the graph. A node defines an operation to update the state, and a conditional edge determines the node to visit next. Note that for the purpose of submitting feedback to Not Diamond, LangChain's grade_documents method, which [EXPLAIN WHAT THIS DOES] is a clear feedback signal.
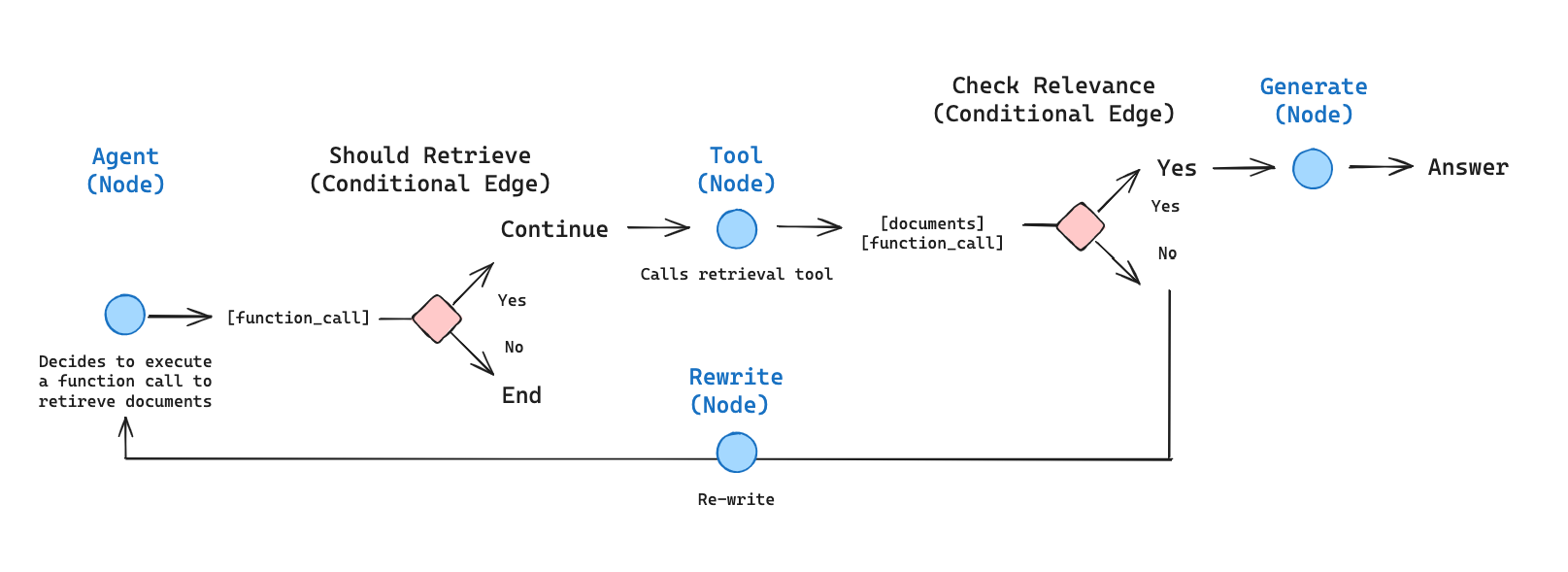
We'll start by describing helper functions to obtain the last state for each node.
def get_last_node_state(state: AgentState, node_name:str) -> AgentState | None:
"""
Get last state for the relevant node.
"""
for s in zip(state["messages"][::-1], state["session_ids"][::-1], state["providers"][::-1], state["node_name"][::-1]):
if s[-1] == node_name:
return {"message": s[0], "session_id": s[1], "provider": s[2], "node_name": s[3]}
return None
def provide_nd_feedback(state: AgentState, node_name: str, metric: str, value: int) -> None:
"""
Provide feedback for the relevant node to Not Diamond.
"""
nd_metric = Metric(metric)
last_state = get_last_node_state(state, node_name=node_name)
if last_state is not None:
session_id = last_state["session_id"]
provider = last_state["provider"]
nd_metric.feedback(session_id=session_id, llm_config=provider, value=value)
def create_nd_preference_id(nd_api_key: str, name: Optional[str] = None) -> str:
"""
Programmatically create a preference ID to create a custom router using feedback.
"""
url = "https://not-diamond-server.onrender.com/v2/preferences/userPreferenceCreate"
headers = {
"Authorization": f"Bearer {nd_api_key}"
}
res = requests.post(
url=url,
headers=headers,
json={"name": name} # You can give the preference a name which will be displayed in the dashboard
)
if res.status_code == 200:
preference_id = res.json()["preference_id"]
return preference_id
else:
raise Exception(f"Error creating preference ID: {res.text}")
nd_preference_id = create_nd_preference_id(os.getenv("NOTDIAMOND_API_KEY"), "agentic_rag_example")Next, we'll define edges of the graph that determine which node will be visited next. The decisions are made by grading the action performed by the associated node, for example by scoring the relevance of retrieved documents, using LLM-as-a-Judge. We can use the binary yes or no scores to provide feedback using Not Diamond's accuracy metric.
Responses are scored at each stepBecause agent workflows involve multiple steps, we want to score our LLM response based on the tools available to the agent and its task at each step, independent of the rest of the workflow.
In this example we use real-time personalization to iteratively improve routing recommendations. We can also generate an evaluation dataset by calling all of our candidate models at each step and scoring each response, which we can then use to train a custom router.
### Edges
# Data model for score
class grade(BaseModel):
"""Binary score for relevance check."""
binary_score: str = Field(description="Relevance score 'yes' or 'no'")
def grade_documents(state: AgentState) -> Literal["generate", "rewrite"]:
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (messages, session_ids, providers, node_name): The current state
Returns:
str: A decision for whether the documents are relevant or not
"""
print("---CHECK RELEVANCE---")
# LLM
model = ChatOpenAI(temperature=0, model="gpt-3.5-turbo", streaming=True)
# LLM with tool and validation
llm_with_tool = model.with_structured_output(grade)
# Prompt
prompt = PromptTemplate(
template="""You are a grader assessing relevance of a retrieved document to a user question. \n
Here is the retrieved document: \n\n {context} \n\n
Here is the user question: {question} \n
If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question.""",
input_variables=["context", "question"],
)
# Chain
chain = prompt | llm_with_tool
messages = state["messages"]
question = messages[0].content
docs = messages[-1].content
scored_result = chain.invoke({"question": question, "context": docs})
score = scored_result.binary_score
if score == "yes":
print("---DECISION: DOCS RELEVANT---")
provide_nd_feedback(state, node_name='rewrite', metric='accuracy', value=1)
return "generate"
else:
print("---DECISION: DOCS NOT RELEVANT---")
provide_nd_feedback(state, node_name='rewrite', metric='accuracy', value=0)
return "rewrite"
def grade_agent(state: AgentState) -> None:
"""
Determines whether tool use should have been called.
Args:
state (messages, session_ids, providers, node_name): The current state
Returns:
None
"""
print("---CHECK GRAPH TERMINATION ACCURACY---")
# LLM
model = ChatOpenAI(temperature=0, model="gpt-4-0125-preview", streaming=True)
# LLM with tool and validation
llm_with_tool = model.with_structured_output(grade)
# Prompt
prompt = PromptTemplate(
template="""You are a grader assessing whether or not a document retriever tool should have been used on the following question.\n
Here is the question: {question} \n
If the question does not require specific knowledge that may be contained in a document store, grade it as yes. \n
Give a binary score 'yes' or 'no' score to indicate whether the question requires specific knowledge that may be contained in a document store.""",
input_variables=["question"],
)
# Chain
chain = prompt | llm_with_tool
messages = state["messages"]
question = messages[-2].content
scored_result = chain.invoke({"question": question})
score = scored_result.binary_score
if score == "yes":
print("---DECISION: GRAPH TERMINATION ACCURATE---")
provide_nd_feedback(state, node_name='agent', metric='accuracy', value=1)
elif score == "no":
print("---DECISION: GRAPH TERMINATION INACCURATE---")
provide_nd_feedback(state, node_name='agent', metric='accuracy', value=0)
def grade_answer(state: AgentState) -> None:
"""
Determines quality of the final answer.
Args:
state (messages, session_ids, providers, node_name): The current state
Returns:
None
"""
print("---CHECK ANSWER ACCURACY---")
# LLM
model = ChatOpenAI(temperature=0, model="gpt-4-0125-preview", streaming=True)
# LLM with tool and validation
llm_with_tool = model.with_structured_output(grade)
# Prompt
prompt = PromptTemplate(
template="""You are a grader assessing the accuracy of an answer to a user question. \n
Here is the relevant context: \n\n {context} \n\n
Here is the user question: {question} \n
Here is the answer: {answer} \n
If the answer correctly answers the question given the relevant context, grade it as correct. \n
Give a binary score 'yes' or 'no' score to indicate whether the answer is correct.""",
input_variables=["context", "question", "answer"],
)
# Chain
chain = prompt | llm_with_tool
messages = state["messages"]
docs = messages[-2].content
question = messages[0].content
answer = messages[-1].content
scored_result = chain.invoke({"question": question, "context": docs, "answer": answer})
score = scored_result.binary_score
if score == "yes":
print("---DECISION: THE ANSWER IS CORRECT---")
provide_nd_feedback(state, node_name='generate', metric='accuracy', value=1)
else:
print("---DECISION: THE ANSWER IS INCORRECT---")
provide_nd_feedback(state, node_name='generate', metric='accuracy', value=0)With out graph's edges in place, we can define our nodes: namely, agent that decides whether to retrieve using the retrieval tool, rewrite that rewrites the input query for improved retrieval if required, and generate that generates the answer using the retrieved content. Each node involves a model call, and so we can use Not Diamond's routing and feedback mechanisms for each node.
def agent(state: AgentState):
"""
Invokes the agent model to generate a response based on the current state. Given
the question, it will decide to retrieve using the retriever tool, or simply end.
Args:
state (messages, session_ids, providers, node_name): The current state
Returns:
dict: The updated state with agent response, session id, selected model, and node name
"""
print("---CALL AGENT---")
messages = state["messages"]
prompt = messages[0].content
llm_providers = [
'openai/gpt-3.5-turbo',
'openai/gpt-4-turbo-2024-04-09',
'openai/gpt-4o-2024-05-13',
'anthropic/claude-3-haiku-20240307',
'anthropic/claude-3-opus-20240229'
]
client = NotDiamond(llm_configs=llm_providers)
client.bind_tools(tools)
result, session_id, provider = client.chat.completions.create(
messages = [{"role": "user", "content": prompt}],
preference_id=nd_preference_id
)
# We return a list, because this will get added to the existing list
return {
"messages": [result],
"session_ids": [session_id],
"providers": [provider],
"node_name": ["agent"],
}
def rewrite(state):
"""
Transform the query to produce a better question.
Args:
state (messages, session_ids, providers, node_name): The current state
Returns:
dict: The updated state with re-phrased question, session id, selected model, and node name
"""
print("---TRANSFORM QUERY---")
messages = state["messages"]
question = messages[0].content
rewrite_prompt = f""" \n
Look at the input and try to reason about the underlying semantic intent / meaning. \n
Here is the initial question:
\n ------- \n
{question}
\n ------- \n
Formulate an improved question: """
llm_providers = [
'openai/gpt-3.5-turbo',
'openai/gpt-4-turbo-2024-04-09',
'openai/gpt-4o-2024-05-13',
'anthropic/claude-3-haiku-20240307',
'anthropic/claude-3-opus-20240229'
]
client = NotDiamond(llm_configs=llm_providers)
result, session_id, provider = client.chat.completions.create(
messages=[{"role": "user", "content": rewrite_prompt}],
preference_id=nd_preference_id
)
return {
"messages": [result],
"session_ids": [session_id],
"providers": [provider],
"node_name": ["rewrite"],
}
def generate(state):
"""
Generate answer
Args:
state (messages): The current state
Returns:
dict: The updated state with the generated answer, session id, selected model, and node name
"""
print("---GENERATE---")
messages = state["messages"]
question = messages[0].content
last_message = messages[-1]
docs = last_message.content
# Prompt
generate_prompt = f"""
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {docs}
Answer:
"""
llm_providers = [
'openai/gpt-3.5-turbo',
'openai/gpt-4-turbo-2024-04-09',
'openai/gpt-4o-2024-05-13',
'anthropic/claude-3-haiku-20240307',
'anthropic/claude-3-opus-20240229'
]
client = NotDiamond(llm_configs=llm_providers)
result, session_id, provider = client.chat.completions.create(
messages=[{"role": "user", "content": generate_prompt}],
preference_id=nd_preference_id
)
return {
"messages": [result],
"session_ids": [session_id],
"providers": [provider],
"node_name": ["generate"],
}Graph
Finally, we construct a graph that starts with the agent to decide whether to retrieve using the retriever tool. If the retriever tool is called, then the relevance of the retrieved content is determined. If the retrieved content is relevant, the generate node is called to generate an answer using the retrieved content and its generation is score. Otherwise the rewrite node is called to re-phrase the query and start over.
# Define a new graph
workflow = StateGraph(AgentState)
# Define the nodes we will cycle between
workflow.add_node("agent", agent) # agent
retrieve = ToolNode([retriever_tool])
workflow.add_node("retrieve", retrieve)
workflow.add_node("rewrite", rewrite) # Re-writing the question
workflow.add_node("grade_answer", grade_answer)
workflow.add_node("grade_agent", grade_agent)
workflow.add_node("generate", generate) # Generate a response if the documents are relevant
# Call agent node to decide to retrieve or not
workflow.add_edge(START, "agent")
# Decide whether to retrieve
workflow.add_conditional_edges(
"agent",
# Assess agent decision
tools_condition,
{
# Translate the condition outputs to nodes in our graph
"tools": "retrieve",
END: "grade_agent",
},
)
workflow.add_edge("grade_agent", END)
# Edges taken after the `action` node is called.
workflow.add_conditional_edges(
"retrieve",
# Assess retrieved documents
grade_documents,
)
workflow.add_edge("generate", "grade_answer")
workflow.add_edge("grade_answer", END)
workflow.add_edge("rewrite", "agent")
# Compile
graph = workflow.compile()Try it
Run the following code to execute the compiled graph and see the agentic RAG workflow with Not Diamond in action.
# Create inputs and execute graph
inputs = {
"messages": [
("user", "What does Lilian Weng say about the types of agent memory?"),
]
}
for output in graph.stream(inputs):
for key, value in output.items():
pprint.pprint(f"Output from node '{key}':")
pprint.pprint("---")
pprint.pprint(value, indent=2, width=80, depth=None)
pprint.pprint("\n---\n")Updated 11 days ago