Human-in-the-loop routing
LLMs are proficient on about 80% of tasks—it’s the last 20% that often prevents a project from reaching production. The “human-in-the-loop” approach is designed to close this gap by leveraging a human expert to review LLM outputs. But how do you determine when to use human verification? Requiring humans to review millions or billions of outputs a day is not very efficient, and LLMs themselves are notoriously bad at identifying when they have made a mistake. It's also not a good experience for end users if they're forced to decipher when an LLM is misleading them and then request human assistance.
To solve this problem, we need to be able to accurately predict exactly when a query can be answered by an LLM and when it should go to a human expert.
In this tutorial, we will use Not Diamond to build a custom router that determines when a query can be answered by an LLM and when it should go to a human. We’ll then use LangGraph to to build an app that routes queries between LLMs and humans. You can follow along with the example below or in this notebook.
Train a custom router
To build a custom router, we first need data on the LLMs we are interested in routing between as well as define a custom model that represents a human.
For the purpose of this example, we’ll use a prepared dataset, which has evaluation results of the following models on the GPQA dataset.
claude-3-5-sonnet-20240620claude-3-opus-20240229gpt-4o-2024-05-13gpt-4-turbo-2024-04-09gemini-1.5-pro-latest
!curl -L "https://drive.google.com/uc?export=download&id=1MWyjjaZsgnp8xDQ0q7chKaT7HxFJlCT1" -o gpqa.csv
!apt install graphviz libgraphviz-dev pkg-config
!pip install -q notdiamond[create] pandas langgraph langchain-anthropic langchain-openai langchain-google-genai pygraphviz --upgradeimport os
os.environ["NOTDIAMOND_API_KEY"] = 'YOUR_NOTDIAMOND_API_KEY'
os.environ["OPENAI_API_KEY"] = 'YOUR_OPENAI_API_KEY'
os.environ["ANTHROPIC_API_KEY"] = 'YOUR_ANTHROPIC_API_KEY'
os.environ["GOOGLE_API_KEY"] = 'YOUR_GOOGLE_API_KEY'from IPython.display import display
import pandas as pd
from pprint import pprint
from notdiamond.toolkit import CustomRouter
from notdiamond import NotDiamond
# Load the dataset
df = pd.read_csv('gpqa.csv')
# Display the column names to ensure it's loaded correctly
pprint(df.columns)Dataset preparation
Inside the dataset, each LLM has a response and final_score column, recording the response of the LLM to the Input and the score of the response. Scores are given as a binary, 0 for wrong answers, and 1 for correct answers.
We will first define a human as a custom model to the custom router
from notdiamond.llms.config import LLMConfig
human = LLMConfig(
provider="hr",
model="human",
is_custom=True,
context_length=100000000,
input_price=1e6, # USD per million tokens
output_price=1e6, # USD per million tokens
latency=1e6 # time to first token (seconds)
)Here, we’ve used the LLMConfig class to define a custom model by setting is_custom=True. When defining a custom model, we need to tell Not Diamond the context_length, input_price, output_price, and latency of the model. Since we’re defining a human, we can set these values to be large.
Next, we’ll give the human model a score on the Input of the dataset. Since we don’t actually have human written responses, we can simply give the human model a score of 1 if the most performant models in the dataset did not respond to a query correctly. In essence, this tells the router that when a query is hard, send it to a human.
top_providers = [
"openai/gpt-4o-2024-05-13",
"openai/gpt-4-turbo-2024-04-09",
"anthropic/claude-3-5-sonnet-20240620",
]
def create_human_score(row):
llm_scores = []
for col, val in row.items():
if "final_score" in col and any([x in col for x in top_providers]):
llm_scores.append(val)
if sum(llm_scores) < len(top_providers):
return 1.
else:
return 0.
def create_human_response(row):
return "Your question will be directed to the next available agent."
df[f"{human.provider}/{human.model}/final_score"] = df.apply(create_human_score, axis=1)
df[f"{human.provider}/{human.model}/response"] = df.apply(create_human_response, axis=1)
pprint(df.columns)Finally, we will process the dataset into a dictionary of pandas.DataFrame because that’s what the notdiamond.toolkit.CustomRouter expects
# List of LLM providers
llm_providers = [
"openai/gpt-4o-2024-05-13",
"openai/gpt-4-turbo-2024-04-09",
"google/gemini-1.5-pro-latest",
"anthropic/claude-3-opus-20240229",
"anthropic/claude-3-5-sonnet-20240620",
human
]
# Dictionaries to hold train and test splits for each provider
pzn_train = {}
pzn_test = {}
# Separating the data and creating the splits
for provider in llm_providers:
provider_results = df.filter(
["Input", f"{str(provider)}/response", f"{str(provider)}/final_score"], axis=1
)
provider_results.rename(
columns={
f"{str(provider)}/response": "response",
f"{str(provider)}/final_score": "score"
},
inplace=True
)
# Create train/test split
train = provider_results.sample(frac=0.9, random_state=42)
test = provider_results.drop(train.index)
pzn_train[provider] = train
pzn_test[provider] = test
# Display the number of samples in each split for the first provider as a sanity check
provider = llm_providers[0]
pprint(f"Train samples: {len(pzn_train[provider])}")
pprint(f"Test samples: {len(pzn_test[provider])}")Train the custom router
To train the custom router, just call the CustomRouter.train method using the dataset we have prepared
# Initialize the CustomRouter object for training
trainer = CustomRouter(
language="english",
maximize=True, # Indicate if higher scores are better (setting to False indicates the opposite)
)
# Train the model using your dataset
preference_id = trainer.fit(
dataset=pzn_train, # The dataset containing inputs, responses, and scores
prompt_column="Input", # Column name for the input prompts
response_column="response", # Column name for the model responses
score_column="score" # Column name for the scores
)
print(preference_id)Note that this will return a preference ID preference_id which we will use later to make API requests to Not Diamond. The training takes a couple of minutes and you can track the training status in the Not Diamond Dashboard.

Evaluate the custom router
Once the custom router is trained, you can evaluate it on the test set we prepared earlier
# Evaluate the custom router using the test dataset
results = trainer.eval(
dataset=pzn_test,
prompt_column="Input",
response_column="response",
score_column="score",
preference_id=preference_id
)
# Split the results into eval_results and eval_stats
eval_results, eval_stats = results
# Print the evaluation results and statistics
display(eval_results)
display(eval_stats)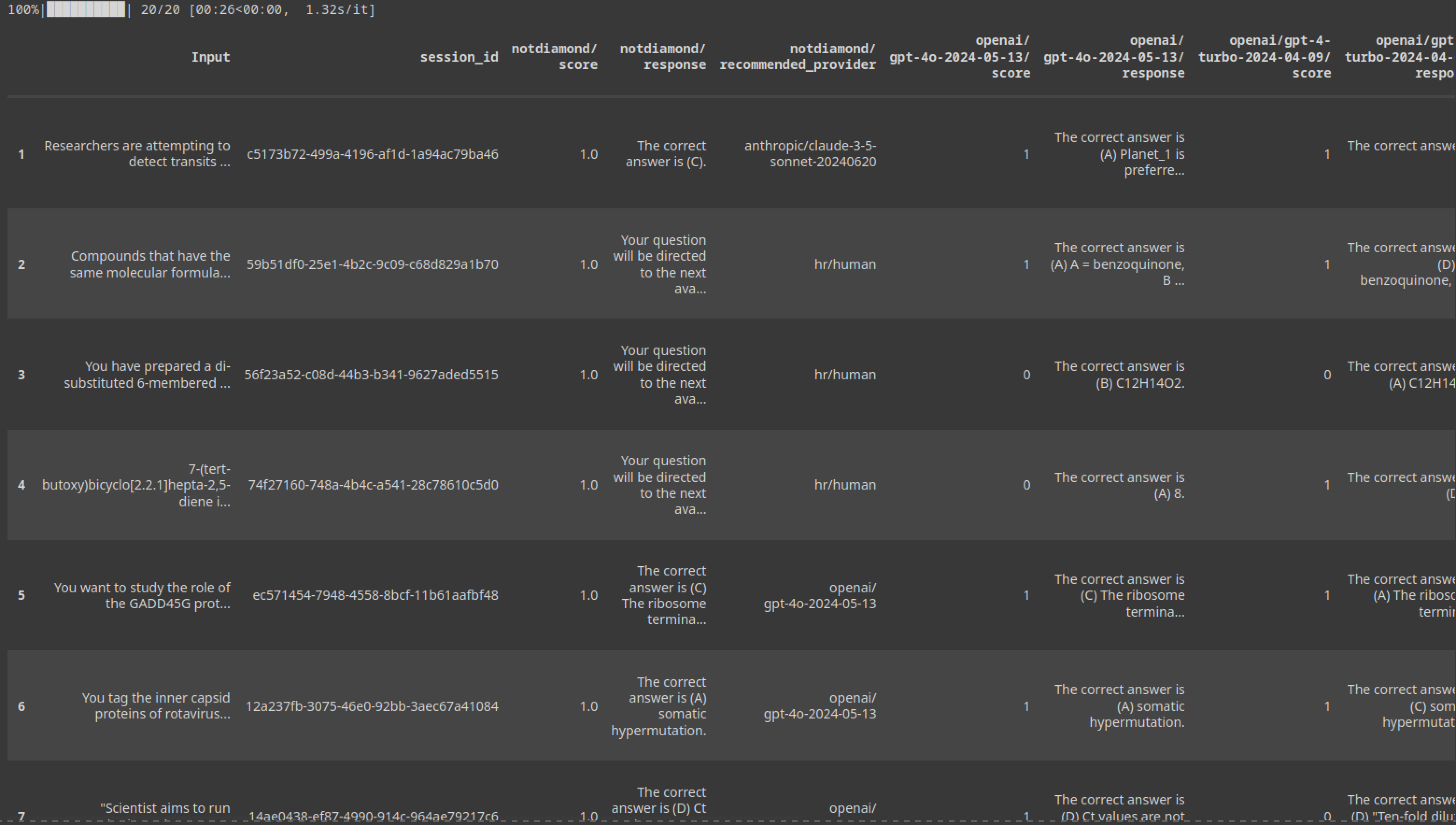

As we can see, using Not Diamond we achieve human grade performance while also sending a significant volume of queries to LLMs.
Human-in-the-loop
With the custom router trained, we can now build our human-in-the-loop app. We will build a simple graph, where the input query goes to our custom router to determine the best LLM or human to call.
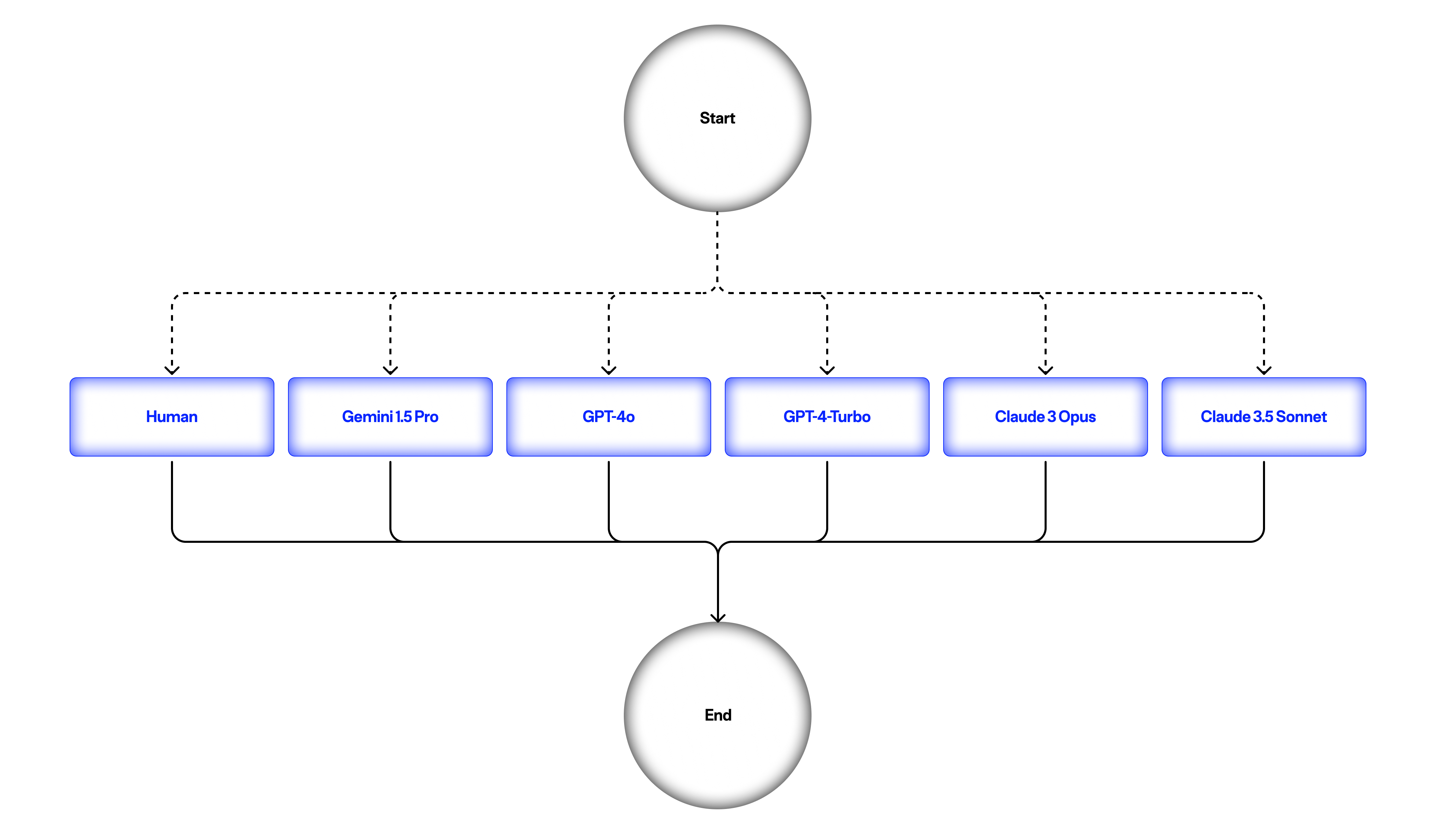
First we'll define all the nodes and our router method
from langgraph.graph import MessagesState, StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
from langchain_core.messages import HumanMessage, AIMessage
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_anthropic import ChatAnthropic
from langchain_openai import ChatOpenAI
from notdiamond import NotDiamond
gemini_15_pro = ChatGoogleGenerativeAI(model="gemini-1.5-pro")
claude_3_opus = ChatAnthropic(model="claude-3-opus-20240229")
claude_35_sonnet = ChatAnthropic(model="claude-3-5-sonnet-20240620")
gpt_4_turbo = ChatOpenAI(model="gpt-4-turbo-2024-04-09")
gpt_4o = ChatOpenAI(model="gpt-4o-2024-05-13")
notdiamond = NotDiamond()
def router(state):
session_id, provider = notdiamond.model_select(
messages=[{"role": "user", "content": state["messages"][-1].content}],
model=llm_providers,
preference_id=preference_id
)
return provider.model
def ask_gpt_4o(state):
response = gpt_4o.invoke(
state["messages"]
)
response.content = f"This question was answered by gpt-4o-2024-05-13:\n\n{response.content}"
return {"messages": [response]}
def ask_gpt_4_turbo(state):
response = gpt_4_turbo.invoke(
state["messages"]
)
response.content = f"This question was answered by gpt-4-turbo-2024-04-09:\n\n{response.content}"
return {"messages": [response]}
def ask_claude_3_opus(state):
response = claude_3_opus.invoke(
state["messages"]
)
response.content = f"This question was answered by claude-3-opus-20240229:\n\n{response.content}"
return {"messages": [response]}
def ask_claude_3_5_sonnet(state):
response = claude_35_sonnet.invoke(
state["messages"]
)
response.content = f"This question was answered by claude-3-5-sonnet-20240620:\n\n{response.content}"
return {"messages": [response]}
def ask_gemini_15_pro(state):
response = gemini_15_pro.invoke(
state["messages"]
)
response.content = f"This question was answered by gemini-1.5-pro-latest:\n\n{response.content}"
return {"messages": [response]}
def ask_human(state):
passNext, connect the nodes and define the conditional edge
workflow = StateGraph(MessagesState)
workflow.add_node("ask_human", ask_human)
workflow.add_node("ask_gemini_15_pro", ask_gemini_15_pro)
workflow.add_node("ask_gpt_4o", ask_gpt_4o)
workflow.add_node("ask_gpt_4_turbo", ask_gpt_4_turbo)
workflow.add_node("ask_claude_3_opus", ask_claude_3_opus)
workflow.add_node("ask_claude_3_5_sonnet", ask_claude_3_5_sonnet)
workflow.add_conditional_edges(
START,
router,
{
"human": "ask_human",
"gemini-1.5-pro-latest": "ask_gemini_15_pro",
"gpt-4o-2024-05-13": "ask_gpt_4o",
"gpt-4-turbo-2024-04-09": "ask_gpt_4_turbo",
"claude-3-opus-20240229": "ask_claude_3_opus",
"claude-3-5-sonnet-20240620": "ask_claude_3_5_sonnet"
}
)
workflow.add_edge("ask_human", END)
workflow.add_edge("ask_gemini_15_pro", END)
workflow.add_edge("ask_gpt_4o", END)
workflow.add_edge("ask_gpt_4_turbo", END)
workflow.add_edge("ask_claude_3_opus", END)
workflow.add_edge("ask_claude_3_5_sonnet", END)
# Set up memory
memory = MemorySaver()
# Compile app
app = workflow.compile(checkpointer=memory, interrupt_before=["ask_human"])
display(Image(app.get_graph().draw_png()))Finally, run the app!
config = {"configurable": {"thread_id": "1"}}
input = """Astronomers are searching for exoplanets around two stars with exactly the same masses. Using the RV method, they detected one planet around each star, both with masses similar to that of Neptune. The stars themselves have masses similar to that of our Sun. Both planets were found to be in circular orbits.
Planet #1 was detected from the up to 5 miliangstrom periodic shift of a spectral line at a given wavelength. The periodic wavelength shift of the same spectral line in the spectrum of the host of planet #2 was 7 miliangstrom.
The question is: How many times is the orbital period of planet #2 longer than that of planet #1?
Choices:
(A) ~ 0.36
(B) ~ 0.85
(C) ~ 1.96
(D) ~ 1.40"""
query = {
"messages": [HumanMessage(content=input)]
}
for event in app.stream(query, config, stream_mode="values"):
event["messages"][-1].pretty_print()================================ Human Message =================================
Astronomers are searching for exoplanets around two stars with exactly the same masses. Using the RV method, they detected one planet around each star, both with masses similar to that of Neptune. The stars themselves have masses similar to that of our Sun. Both planets were found to be in circular orbits.
Planet #1 was detected from the up to 5 miliangstrom periodic shift of a spectral line at a given wavelength. The periodic wavelength shift of the same spectral line in the spectrum of the host of planet #2 was 7 miliangstrom.
The question is: How many times is the orbital period of planet #2 longer than that of planet #1?
Choices:
(A) ~ 0.36
(B) ~ 0.85
(C) ~ 1.96
(D) ~ 1.40
================================== Ai Message ==================================
This question was answered by claude-3-5-sonnet-20240620:
Let's approach this step-by-step:
1) The radial velocity (RV) method detects planets by measuring the periodic Doppler shift in the star's spectrum caused by the planet's gravitational pull.
2) The amplitude of this shift (K) is related to the planet's orbital period (P) by the equation:
K ∝ M_p * P^(-1/3)
Where M_p is the planet's mass.
3) We're told that both planets have similar masses (like Neptune), and both stars have similar masses (like the Sun). This means we can consider M_p to be the same for both planets.
4) The amplitude of the shift (K) is directly proportional to the observed wavelength shift. For planet #1, this is 5 miliangstrom, and for planet #2, it's 7 miliangstrom.
5) Let's call the period of planet #1 P1 and the period of planet #2 P2. We can set up the proportion:
5 ∝ P1^(-1/3)
7 ∝ P2^(-1/3)
6) Dividing these:
5/7 = (P2/P1)^(1/3)
7) Cubing both sides:
(5/7)^3 = P2/P1
8) (5/7)^3 ≈ 0.51
9) This means P2 ≈ 0.51 * P1, or P1 ≈ 1.96 * P2
Therefore, the orbital period of planet #1 is about 1.96 times longer than that of planet #2.
The answer that best matches this is (C) ~ 1.96.This query got routed to claude-3-5-sonnet-20240620! Now let’s try another example
config = {"configurable": {"thread_id": "2"}}
input = """You have prepared a di-substituted 6-membered aromatic ring compound. The FTIR spectrum of this compound shows absorption peaks indicating the presence of an ester group. The 1H NMR spectrum shows six signals: two signals corresponding to aromatic-H, two signals corresponding to vinyl-H (one doublet and one doublet of quartets), and two signals corresponding to –CH3 groups. There are no signals corresponding to –CH2 groups. Identify the chemical formula of this unknown compound as either C11H12O2, C11H14O2, C12H12O2, or C12H14O2.
Choices:
(A) C12H12O2
(B) C11H12O2
(C) C11H14O2
(D) C12H14O2"""
query = {
"messages": [HumanMessage(content=input)]
}
for event in app.stream(query, config, stream_mode="values"):
event["messages"][-1].pretty_print()================================ Human Message =================================
You have prepared a di-substituted 6-membered aromatic ring compound. The FTIR spectrum of this compound shows absorption peaks indicating the presence of an ester group. The 1H NMR spectrum shows six signals: two signals corresponding to aromatic-H, two signals corresponding to vinyl-H (one doublet and one doublet of quartets), and two signals corresponding to –CH3 groups. There are no signals corresponding to –CH2 groups. Identify the chemical formula of this unknown compound as either C11H12O2, C11H14O2, C12H12O2, or C12H14O2.
Choices:
(A) C12H12O2
(B) C11H12O2
(C) C11H14O2
(D) C12H14O2Looks like this example triggered the "ask_human" interrupt. If we were building a chat app, we would send this query to a human to further assist with the response. To continue the graph execution, we simply update the state with a message of our choice, and continue to the next node
human_answer = """The correct answer is A"""
response = HumanMessage(content=human_answer)
app.update_state(config, {"messages": [response]}, as_node="ask_human")
for event in app.stream(None, config, stream_mode="values"):
event["messages"][-1].pretty_print()================================ Human Message =================================
The correct answer is AConclusion
In this example, we showed how you can train a custom router using your own data, leveraging both LLMs and human-in-the-loop to make your LLM powered apps more reliable.
To try out this example, sign up to get a Not Diamond API key and run the example in this notebook.
Updated 8 days ago